第 11 章 - 網路
下載一個網頁
程式: pageget.js
var http = require('http');
http.get("http://www.nqu.edu.tw/cht/index.php?", function(res) {
console.log("Got response: " + res.statusCode);
res.on('data', function (chunk) {
console.log('BODY: ' + chunk);
});
}).on('error', function(e) {
console.log("Got error: " + e.message);
});
執行結果
NQU-192-168-60-101:crawler csienqu$ node pageget.js
Got response: 200
BODY: <!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html lang="zh-TW">
<head>
<title>國立金門大學-></title>
...
</body>
</html>
抽取出網頁中的超連結
檔案: listurl.js
var fs = require('fs');
var html = fs.readFileSync(process.argv[2]).toString();
var r = /href\s*=\s*"(.+?)"/gi;
while (true) {
var m = r.exec(html);
if (!m) break;
console.log(m[1]);
}
執行結果:
NQU-192-168-60-101:regexp csienqu$ ls
copyfile.js listurl.js nqu.html nqu.html.bak readfile.js readline.js
NQU-192-168-60-101:regexp csienqu$ node listurl nqu.html
../cache/css194.css
../js/calendar/calendar-mos.css
index.php
index.php?act=sitemap
index.php
...
網頁爬蟲
以下程式可以《下載全世界的網頁》,只要你記憶體和硬碟夠大就行了!
專案下載: crawler.zip
程式: crawler.js
// 安裝套件: npm install URIjs
// 執行方法: node crawler http://tw.msn.com/
var fs = require('fs');
var http = require('http');
var URI = require('URIjs');
var c = console;
var urlMap = { };
var urlList = [ ];
var urlIdx = 0;
urlList.push(process.argv[2]); // 新增第一個網址
crawNext(); // 開始抓
function crawNext() { // 下載下一個網頁
if (urlIdx >= urlList.length)
return;
var url = urlList[urlIdx];
if (url.indexOf('http://')!==0) {
urlIdx ++;
crawNext();
return;
}
c.log('url[%d]=%s', urlIdx, url);
urlMap[url] = { downlioad:false };
pageDownload(url, function (data) {
var page = data.toString();
urlMap[url].download = true;
var filename = urlToFileName(url);
fs.writeFile('data/'+filename, page, function(err) {
});
var refs = getMatches(page, /\shref\s*=\s*["'#]([^"'#]*)[#"']/gi, 1);
for (i in refs) {
try {
var refUri = URI(refs[i]).absoluteTo(url).toString();
c.log('ref=%s', refUri);
if (refUri !== undefined && urlMap[refUri] === undefined)
urlList.push(refUri);
} catch (e) {}
}
urlIdx ++;
crawNext();
});
}
// 下載一個網頁
function pageDownload(url, callback) {
http.get(url, function(res) {
res.on('data', callback);
}).on('error', function(e) {
console.log("Got error: " + e.message);
});
}
// 取得正規表達式比對到的結果成為一個陣列
function getMatches(string, regex, index) {
index || (index = 1); // default to the first capturing group
var matches = [];
var match;
while (match = regex.exec(string)) {
matches.push(match[index]);
}
return matches;
}
// 將網址改寫為合法的檔案名稱
function urlToFileName(url) {
return url.replace(/[^\w]/gi, '_');
}
執行方法
NQU-192-168-60-101:crawler csienqu$ npm install URIjs
NQU-192-168-60-101:crawler csienqu$ node crawler http://tw.msn.com/
....
一對一聊天
- 一對一聊天下載: chat11.zip
- 多人聊天室下載: chatroom.zip
執行畫面
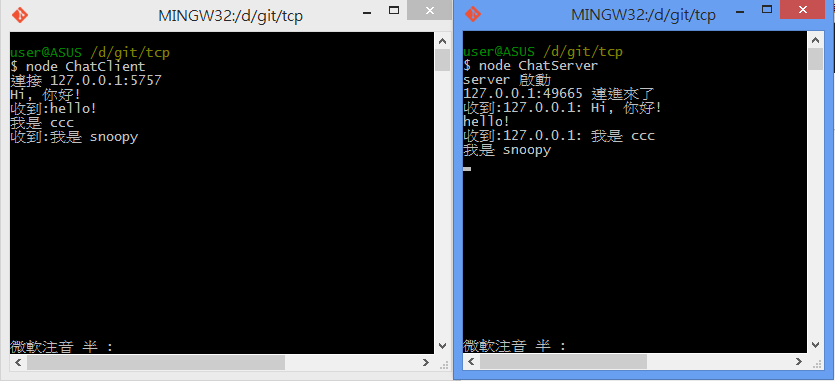
Server 端
檔案: ChatServer.js
var net = require('net');
var readline = require('readline').createInterface(process.stdin, process.stdout);
var server = net.createServer();
server.on('connection', function(sock) {
console.log(sock.remoteAddress +':'+ sock.remotePort+' 連進來了');
readline.setPrompt('');
readline.prompt();
readline.on('line', function(line) {
sock.write(line);
readline.prompt();
});
sock.on('data', function(data) {
console.log('收到:' + sock.remoteAddress + ': ' + data);
});
});
server.listen(5757);
console.log('server 啟動');
關於 readline 的用法請參考: https://nodejs.org/api/readline.html
Client 端
檔案: ChatClient.js
var net = require('net');
var readline = require('readline').createInterface(process.stdin, process.stdout);
var client = new net.Socket();
readline.on('line', function(line) {
client.write(line);
readline.prompt();
});
client.connect(5757, '127.0.0.1', function() {
console.log('連接 ' + client.remoteAddress + ':' + client.remotePort);
readline.setPrompt('');
readline.prompt();
});
client.on('data', function(data) {
console.log('收到:' + data);
});
習題
- 請寫一對程式,包含 server 與 client,其中 client 可以向 server 查詢系統時間。
- 請改良本章的 Crawler 程式,讓網址與抓回來的內容都改存在 mongodb 資料庫中,而不是放在《記憶體》和《檔案系統》當中